


A Primer on Multi-Head Causal Self-Attention
The neural network layer that kicked off the LLM craze

Lately, I've been writing quite a few series that center around the transformer architecture. For many of those blog posts, I struggle to decide whether I should include the background information necessary to understand attention (greatly increasing the length of the blog post) or I should assume the reader already knows this information (limiting the reach of my audience). Thus, this post is intended to be a compromise between the two positions, allowing me to link this post as background reading in any future blog post that requires knowledge of the nuts and bolts of the attention architecture.
This will be a "living" blog post, in that it will be edited and expanded upon as my own understanding of the architecture grows and deepens. If there are any radically large changes that I make, I will re-email the post out to subscribers for their review. Otherwise, feel free to check back periodically to see how the article has changed!
The Basic Terminology of Multi-Head Causal Self-Attention
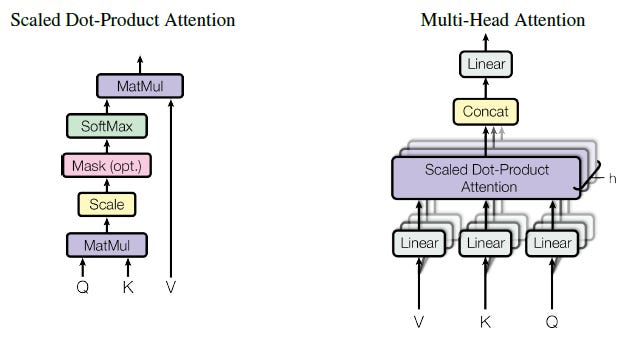
The standard attention block used in first-generation LLMs like GPT-2 and GPT-3 is multi-head casual self-attention.
The goal of this variant of attention, like any attention variant, is to learn how to update a vector using other context vectors in order to accomplish some goal. In the case of language modeling, our vectors represent tokens, which you can think of a roughly analogous to words. The goal of these vector updates is to accurately predict the next word in the sentence. It is called causal because this type of attention ensures that each word can only update itself using previous words in the sentence - that is, it can't look ahead and update itself using words that haven't been written yet! It is called self-attention because the things that each word is paying attention to are the other words in the sentence. There is no outside data or context involved here. And finally, it is termed multi-head because, at each attention layer, we have multiple attention operations occurring in parallel. These parallel attention operators are referred to as "heads".
To produce the results of attention, each attention head takes as input a sequence of tokens represented as vectors. These vectors are passed through three feed-forward networks per head in parallel, projecting each token's vector into three new vectors. These new vectors are commonly referred to as the query, key, and value vectors. These query, key, and value vectors are then used to update the vector representations of the words in our sentence, improving the model's understanding of the concepts contained in the sentence.
Let's take a look at how this is done in practice.
The Mathematics of Causal Self-Attention
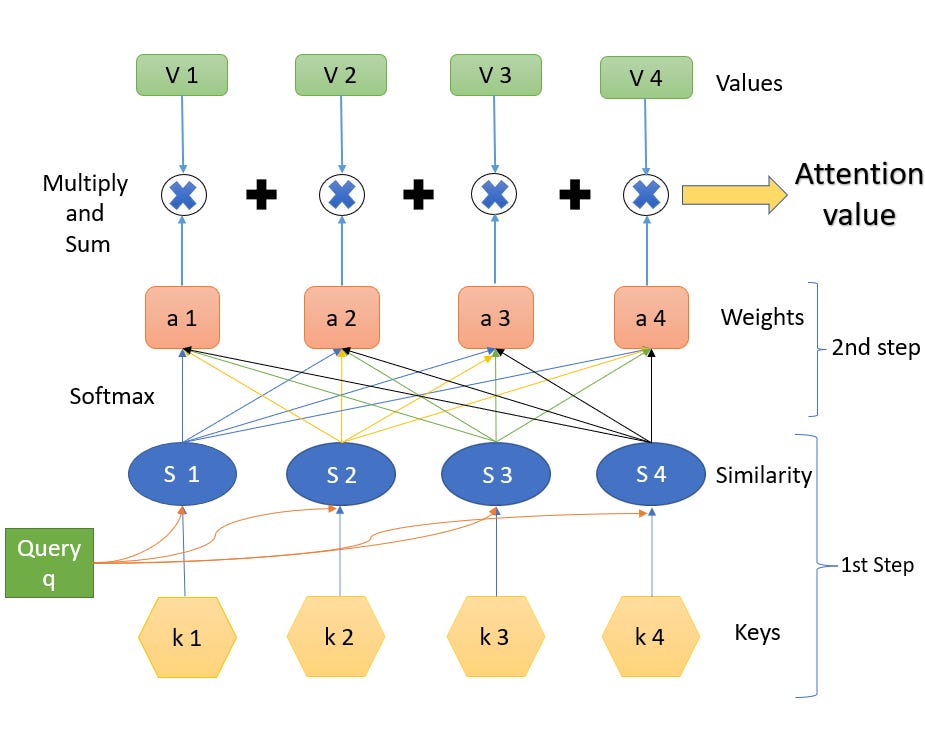
As mentioned, the attention block block takes as input a sequence of tokens represented as vectors. Suppose the input sequence is given by:
where each x_i is the vector representation (embedding) of a token.
Each input vector x_i is simultaneously projected into three different spaces using learned linear transformations. That is, for every token x_i, we compute:
where:
W^Q, W^K, and W^V are the weight matrices for the query, key, and value projections, respectively.
The sets of all query, key, and value vectors are often denoted as Q, K, and V.
For a given token x_i, we will compute a similarity score with every token x_j such that x_j comes before it in the sentence (or is the token itself). This is done by taking the dot product of the query vector for x_i with the key vector for k_j. This result is then divided by the square root of the key vector's dimension. Mathematically, this is given by:
This value is precisely the unnormalized measure of how much token i should attend to token j. In linear algebra, the dot product of two vectors is just a scaled version of the cosine of the angle between them. An angle of 0 degrees gives a cosine value of 1, while an angle of 180 degrees gives a cosine value of -1. Hence, the closer the two vectors get to pointing in the same direction, the closer that their dot product gets to 1, and the closer the two vectors get to pointing in opposite directions, the closer their dot product gets to -1. Intuitively then, cosine (and by extension the dot product) has very desirable properties to use as a similarity function in the attention mechanism.
Armed with these similarity scores, we now have a way of measuring how "similar" two tokens in our sequence are. However, in order to use them to produce new vector embeddings, we're going to want to re-scale them. The dot product between the query and key vectors could end up being quite large, and using this value directly can cause large changes in the scale of the vector representation for a given token. Moreover, knowing the score of a particular token pair (let's say between tokens x_i and x_j) tells us nothing about how important that pair is - importance is always relative, and what if the score for x_i and x_k is bigger?
Given the above discussion we know we need to introduce some function that will re-scale our scores in such a way that we do not radically change the magnitude of the token's vector representation and that we can quickly determine how "important" each token pair is. A convenient differentiable function that does just this is softmax. The equation to produce the softmax output for token x_i is given below:
The softmax function will take our scores for all possible pairs made with x_i (i.e. all key vectors we multiplied by x_i's query vector) and squash them into the range of 0 to 1. Moreover, it will ensure that these values sum to 1. Hence, we can view these outputs, referred to as attention weights, as probabilities or percentages. It can be useful to think of the attention weight for the pair x_i and x_j as the percent of x_i's attention that should be paid to x_j.
Once we have these attention weights, we can use them to produce a new vector representation for token x_i. We do this by taking a weighted sum of the value vectors for each token, where the weight is the attention weight. As mentioned above, we can think of this attention weight as the percent of attention that x_i pays to each vector that precedes it in the sequence. Mathematically, this looks like:
This weighted sum integrates information from the tokens that x_i “attends” to, based on the learned attention weights.
In multi-head attention, these operations happen in parallel multiple times over. That is, we will produce multiple instances of the query, key, and value vectors for each token in the sequence. We will then use those unique instances to produces distinct updated vector representations for each token. If we have k heads, then we will produce k updated vector for token i:
These vectors get concatenated together, forming a single vector to represent the updated token i:
The intuition behind using multiple heads to create the final updated representation for token i is that each head can learn to capture different aspects of language. One had might learn grammatical structure, while another head might learn vocabulary related to the legal profession. By splitting responsibilities between the attention heads, each can learn unique, non-redundant information.
This vector will then be passed through a linear projection layer, producing the final output of the multi-head attention layer.
Let's walk through a toy example now to make things concrete.
A Toy Example: "the dog barks"
Suppose our sentence is "the dog barks", and our tokenizer splits it into three tokens: "the", "dog", and "barks". Initially, these tokens are embedded into vectors:
When entering the first attention block, each of these vectors is projected into three new vectors:
Thus, we transform 3 input vectors into 9 new vectors (3 each for queries, keys, and values).
Updating the "dog" Token
Let’s focus on updating the token "dog". In our example, "dog" corresponds to the second token x_2. To update its representation, we use its query vector and compute dot-product scores with the key vectors of "the" and "dog" (i.e., the tokens that precede or are the token itself):
where d_k is the dimensionality of the key vectors. The division by the square root of d_k is used to normalize the scores.
These scores are then passed through a softmax function to obtain attention weights (or probabilities) that indicate how much attention "dog" should pay to itself and to "the":
Softmax ensures that these attention weights are between 0 and 1, and that they all sum to 1. Hence, they are valid probabilities and, to make things easier, you can of what percent of its attention the word "dog" should pay to the word "the" or to itself.
With the attention probabilities computed, we update the original vector representation of "dog" by taking a weighted sum of the corresponding value vectors. In this case, we combine the value vector of "the" and the value vector of "dog":
This new vector is an updated representation that incorporates contextual information from the preceding token "the" as well as from "dog" itself.
Recap
To recap, these are the major steps for updating the "dog" vector in our example using causal self-attention:
1. Input Embedding:
Each token is embedded into a vector x_i.
2. Linear Projections:
Each x_i is projected into query, key, and value vectors:
3. Score Calculation (for causal attention):
For token "dog" (second token), calculate:
4. Softmax to Obtain Weights:
Convert scores to probabilities:
5. Contextual Update:
Update "dog" by a weighted sum of the value vectors:
In the full multi-head attention mechanism, this process is performed in parallel over multiple "heads" (with different learned projections), and the results are concatenated and transformed further to form the final output of the attention block.
Key Takeaways
Let's now summarize the key points of what we've learned:
Attention is a neural network mechanism used to update vectors using the context from other vectors
Input vectors to an attention layer are replaced by 3 intermediate vectors: the query, key, and value vectors
The query and key vectors work together to produce similarity scores between pairs of vectors. If we are updating token i and want to know how much token j should influence our input, we multiply the query vector of token i by the key vector of token j.
The scores produced by the query and key vectors can be turned into probabilities using the softmax function. These probabilities are used to measure how much token i should consider the tokens that came before it in the sequence when updating its vector representation
The new vector representation for token i is produced by multiplying the softmax probabilities by the value vectors for each corresponding token. These are then summed together
The above process occurs independently across several parallel attention operations, called heads. At the end of the attention block, the new vector representations for token i coming from each head are concatenated together and passed through a linear projection layer.
The above process (steps 1-6) is performed in parallel for the full sequence of input tokens.
If you keep these 7 key points in mind while reading Arxiv papers (or my future blog posts!), you'll have a strong understanding of what multi-head causal self-attention is doing, where it faces limitations, and whether or not a given architectural change actually addresses those limitations.
Really clean and effective explanation! I definitely had a very intuitively weak understanding of the attention mechanism until now.
Would be interesting to see why specifically causal attention seems to be the norm. From my initial understanding any tokens before the end of the input sequence could technically take into account future tokens. Intuitively it seems to make sense too - the context of any given word can be affected by a future word.
Maybe it's the performance impact of having to recalculate the attention? Even then it feels like it would be possible to do this intermittently at least or maybe exclude some transformer blocks. Pretty sure I'm missing something with that.